
As all, I started with Midjourney (free option) until I run out of credits. Stable Diffusion was the answer.
Concept of AI image generation using text input (text-to-image)
According to the internet*: (AI) image generation using text input (a.k.a. text-to-image) is a field of artificial intelligence (AI) that focuses on generating realistic images from textual descriptions.
The goal is to create an AI system that can understand natural language and use that understanding to create images that accurately represent the text. The text input can describe a scene, an object, or even an abstract concept, and the AI system generates an image that matches the description.
Text-to-image synthesis has many potential applications, such as in creative fields like art and design, as well as in areas like computer vision and robotics.
Stable Diffusion
Stable Diffusion is one of many AI image generators that allows users to create art from their text input (text-to-image).
Stable Diffusion is a deep learning model that uses a diffusion process to generate images from text descriptions. The Stable Diffusion model is based on a powerful AI architecture called GPT-3, which is known for its ability to understand and generate natural language.
What I like about Stable Diffusion is able to create high-quality images that match text input and doest and extra “filters” (unless intended by prompt or your own settings).
The Stable Diffusion was released publicly on August 22 and now anyone can use them to generate images for “free”.
Free, but with *
Why there is “*”? Good that You asked. Because You still need some money to own PC that can handle the requirements of Stable Diffusion. Most costs would go to GPU. With that said, not all old computers will handle a load of image generation using only CPU… or it will be a very long process. Even longer, if need iterate some image or concept.
While minimum-ish NVIDIA graphics card VRAM is “only” ~4GB, ~8GB RAM and some 20GB+ space (will fill very fast).
No code, just UI
While running Stable diffusion in the command line is “cool” and You can feel like a hacker, I prefer some kinda user interface, without writing a single line of code in CMD.
Easy Diffusion / Stable Diffusion UI
I started out with Easy Diffusion (stable-diffusion-ui.github.io). Super easy to install. Download, follow instructions, done.
As with all new toys, I started to play around… and didn’t get any meaningful results. I was expecting something Midjourney like-ish. I just got my weird version of “A photo of an astronaut riding a horse” (in space).
Just for this post, I recreated in “Stable Diffusion Web UI” a similar image with default settings.

Quality and missing legs were something similar. I knew that there must be something that could improve the generated image.
Digging deeper, I found out that I need models. Knowing nothing about them, found another tool.
Stable Diffusion web UI
While trying to install extensions and models to Easy Diffusion, they were “lost” (read the wrong directory). The instructions just were bad.
Found different programms with instructions and similar interface and instructions that worked.
And… switch.
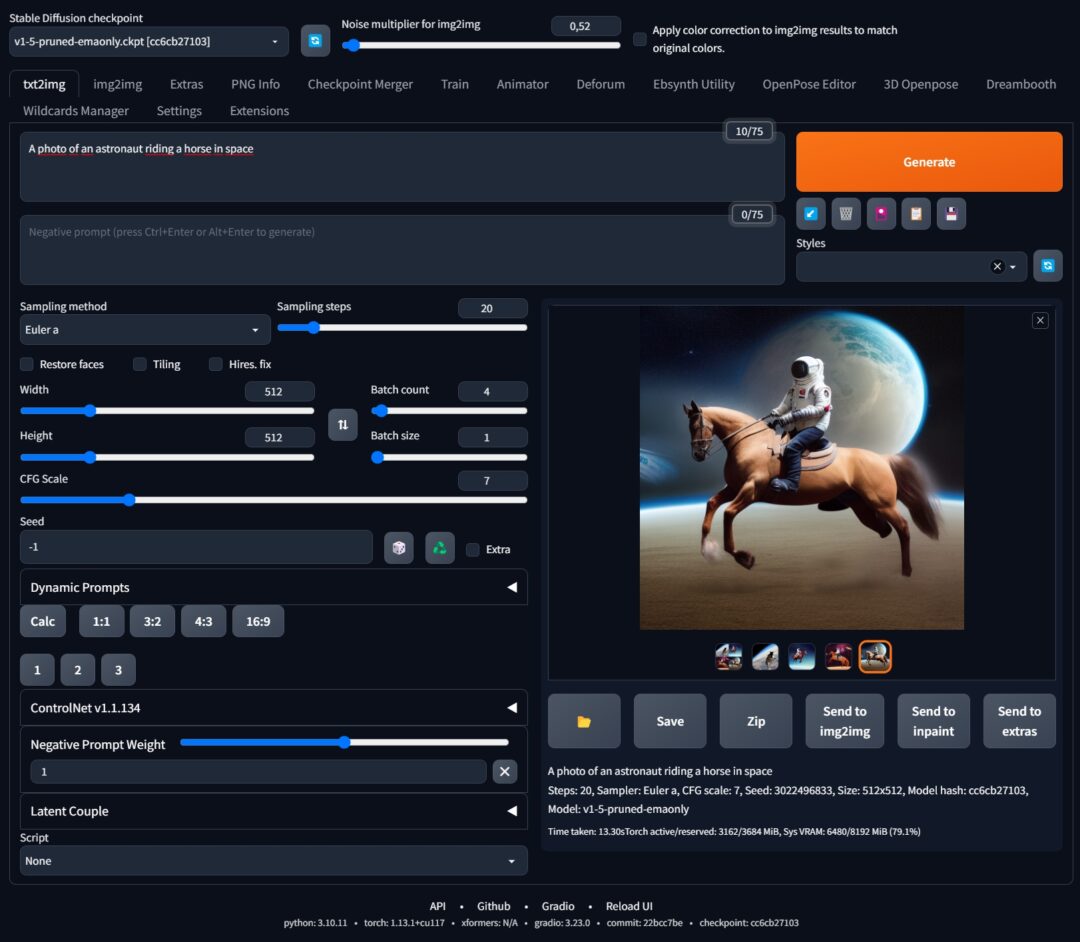
From that moment AUTOMATIC1111’s Stable Diffusion web UI (github.com/AUTOMATIC1111/stable-diffusion-webui) is my choice. Until something better will come out.
Why Stable Diffusion web UI?
Ease of use, layout and easier to extend. That’s it. And uncensored.
The risks of using Stable Diffusion
((((NSFW)))) and ((((nude))))
Because it’s uncensored, depending on the models You use, it may (and will) produce “not safe for work” (NSFW) content and nudes. That is the reason all of my prompt’s negatives start with “((((nsfw)))), ((((nude)))), (((child)))”. Since I don`t need a bunch of images of children, I also include “child” as and negative work.
Fun fact: NSFW models produce better skin texture in generated photos, so it looks natural. Tried several restricted models and most of them could not produce detailed skin texture. So, turning the “bad” model into useful.
Currently, my go-to sites for new Stable Diffusion models are civit.ai and huggingface.co/models?other=stable-diffusion.
Trained on small images
Maybe it is just me, but I like images that are at least 1024px big (I also have a 4K monitor, so…), but most models in Stable Diffusion 1.5 are trained on 512x512px images, some maybe 768×768. I tend to create larger images on the first runs, just to see the spacing and position of objects in images. Using larger canvas size, sometimes lead to undesired photos.
Larger image sizes are in Stable Diffusion 2.0/2.1 (current version at the time of writing this post), where they start at 768×768 and up
*- I just rewrote in my own words what ChatGPT said.
Leave a Reply